Flink-RunTime
Flink-RunTime
架构

这三个组件都包含在 AppMaster 进程中
- Dispatcher: 负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager 服务。
- ResourceManager: 负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager,资源相关的内容都由这个服务负责。
- JobManager: 负责管理具体某个作业的执行,在一个 Flink 集群中可能有多个作业同时执行,每个作业都会有自己的 JobManager 服务。
启动流程
当用户开始提交一个作业,首先会将用户编写的代码转化为一个 JobGraph。
在这个过程中,它会进行一些检查或优化相关的工作(比如:检查配置,把可以 Chain 在一起算子 Chain 在一起)。
然后,Client 再将生成的 JobGraph 提交到集群中执行。
此时有两种情况(对于两种不同类型的集群):
- 类似于 Standalone 这种 Session 模式(对于 YARN 模式来说),这种情况下 Client 可以直接与 Dispatcher 提供的REST接口提交作业;[1]
在 Session 模式下,Flink 预先启动 AppMaster 以及一组 TaskExecutor,然后在整个集群的生命周期中会执行多个作业。可以看出,Session 模式更适合规模小,执行时间短的作业。
- 二是 Per-Job 模式,这种情况下 Client 首先向资源管理系统 (如 Yarn)申请资源来启动 ApplicationMaster,然后再向 ApplicationMaster 中的 Dispatcher 提交作业。
Per-job 模式下整个 Flink 集群只执行单个作业,即每个作业会独享 Dispatcher 和 ResourceManager 组件。此外,Per-job 模式下 AppMaster 和 TaskExecutor 都是按需申请的。因此,Per-job 模式更适合运行执行时间较长的大作业,这些作业对稳定性要求较高,并且对申请资源的时间不敏感。

当作业到 Dispatcher 后,Dispatcher 会首先启动一个 JobManager 服务,然后 JobManager 会向 ResourceManager 申请资源来启动作业中具体的任务。
ResourceManager 选择到空闲的 Slot (Flink 架构-基本概念)之后,就会通知相应的 TM 将该 Slot 分配给指定的 JobManager。
这时根据 Session 和 Per-Job 模式的区别, TaskExecutor 可能已经启动或者尚未启动。如果是前者,此时 ResourceManager 中已有记录了 TaskExecutor 注册的资源,可以直接选取空闲资源进行分配。
否则,ResourceManager 也需要首先向外部资源管理系统申请资源来启动 TaskExecutor,然后等待 TaskExecutor 注册相应资源后再继续选择空闲资源进程分配。
目前 Flink 中 TaskExecutor 的资源是通过 Slot 来描述的,一个 Slot 一般可以执行一个具体的 Task,但在一些情况下也可以执行多个相关联的 Task,这部分内容将在下文进行详述。
ResourceManager 选择到空闲的 Slot 之后,就会通知相应的 TM “将该 Slot 分配分 JobManager XX ”,然后 TaskExecutor 进行相应的记录后,会向 JobManager 进行注册。
JobManager 收到 TaskExecutor 注册上来的 Slot 后,就可以实际提交 Task 了。TaskExecutor 收到 JobManager 提交的 Task 之后,会启动一个新的线程来执行该 Task。
Task 启动后就会开始进行预先指定的计算,并通过数据 Shuffle 模块互相交换数据。
资源管理与作业调度
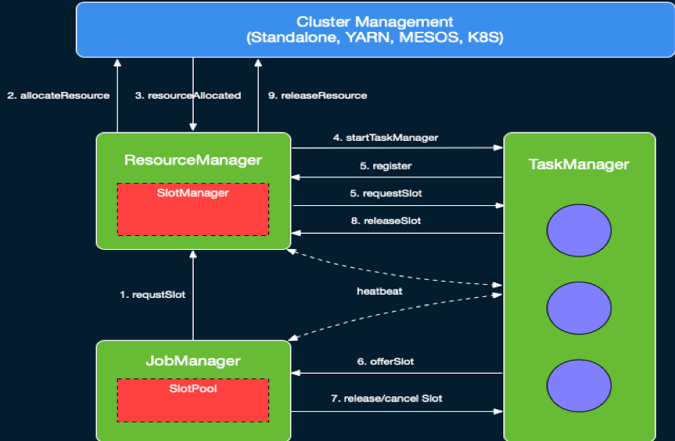
作业调度的基础是首先提供对资源的管理,Flink 中的资源是由 TaskExecutor 上的 Slot 来表示的。
在 ResourceManager 中,有一个子组件叫做 SlotManager,它维护了当前集群中所有 TaskExecutor 上的 Slot 的信息与状态,如该 Slot 在哪个 TaskExecutor 中,该 Slot 当前是否空闲等。
当 JobManger 来为特定 Task 申请资源的时候,根据当前是 Per-job 还是 Session 模式,ResourceManager 可能会去申请资源来启动新的 TaskExecutor。
当 TaskExecutor 启动之后,它会通过服务发现找到当前活跃的 ResourceManager 并进行注册。在注册信息中,会包含该 TaskExecutor中所有 Slot 的信息。
ResourceManager 收到注册信息后,其中的 SlotManager 就会记录下相应的 Slot 信息。当 JobManager 为某个 Task 来申请资源时, SlotManager 就会从当前空闲的 Slot 中按一定规则选择一个空闲的 Slot 进行分配。
当分配完成后,如上节所述,RM 会首先向 TaskManager 发送 RPC 要求将选定的 Slot 分配给特定的 JobManager。TaskManager 如果还没有执行过该 JobManager 的 Task 的话,它需要首先向相应的 JobManager 建立连接,然后发送提供 Slot 的 RPC 请求。
在 JobManager 中,所有 Task 的请求会缓存到 SlotPool 中。当有 Slot 被提供之后,SlotPool 会从缓存的请求中选择相应的请求并结束相应的请求过程。
当 Task 结束之后,无论是正常结束还是异常结束,都会通知 JobManager 相应的结束状态,然后在 TaskManager 端将 Slot 标记为已占用但未执行任务的状态。JobManager 会首先将相应的 Slot 缓存到 SlotPool 中,但不会立即释放。
这种方式避免了如果将 Slot 直接还给 ResourceManager,在任务异常结束之后需要重启时,需要立刻重新申请 Slot 的问题。通过延时释放,Failover 的 Task 可以尽快调度回原来的 TaskManager,从而加快 Failover 的速度。
当 SlotPool 中缓存的 Slot 超过指定的时间仍未使用时,SlotPool 就会发起释放该 Slot 的过程。与申请 Slot 的过程对应,SlotPool 会首先通知 TaskManager 来释放该 Slot,然后 TaskExecutor 通知 ResourceManager 该 Slot 已经被释放,从而最终完成释放的逻辑。
除了正常的通信逻辑外,在 ResourceManager 和 TaskExecutor 之间还存在定时的心跳消息来同步 Slot 的状态。在分布式系统中,消息的丢失、错乱不可避免,这些问题会在分布式系统的组件中引入不一致状态,如果没有定时消息,那么组件无法从这些不一致状态中恢复。
此外,当组件之间长时间未收到对方的心跳时,就会认为对应的组件已经失效,并进入到 Failover 的流程。

在 Slot 管理基础上,Flink 可以将 Task 调度到相应的 Slot 当中。如上文所述,Flink 尚未完全引入细粒度的资源匹配,默认情况下,每个 Slot 可以分配给一个 Task。但是,这种方式在某些情况下会导致资源利用率不高。
如图所示,假如 A、B、C 依次执行计算逻辑,那么给 A、B、C 分配分配单独的 Slot 就会导致资源利用率不高。为了解决这一问题,Flink 提供了 Share Slot 的机制。
如所示,基于 Share Slot,每个 Slot 中可以部署来自不同 JobVertex 的多个任务,但是不能部署来自同一个 JobVertex 的 Task。如所示,每个 Slot 中最多可以部署同一个 A、B 或 C 的 Task,但是可以同时部署 A、B 和 C 的各一个 Task。
当单个 Task 占用资源较少时,Share Slot 可以提高资源利用率。 此外,Share Slot 也提供了一种简单的保持负载均衡的方式。
基于上述 Slot 管理和分配的逻辑,JobManager 负责维护作业中 Task执行的状态。如上文所述,Client 端会向 JobManager 提交一个 JobGraph,它代表了作业的逻辑结构。
JobManager 会根据 JobGraph 按并发展开,从而得到 JobManager 中关键的 ExecutionGraph。ExecutionGraph 的结构如上图所示,与 JobGraph 相比,ExecutionGraph 中对于每个 Task 与中间结果等均创建了对应的对象,从而可以维护这些实体的信息与状态。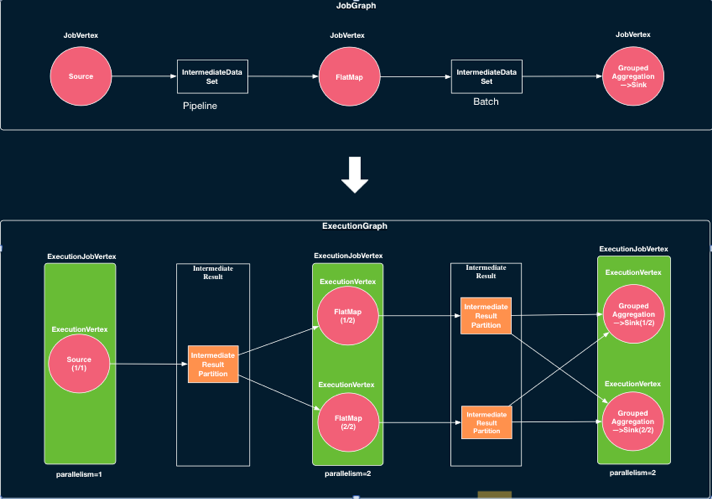
在一个 Flink Job 中是包含多个 Task 的,因此另一个关键的问题是在 Flink 中按什么顺序来调度 Task。如下图所示,目前 Flink 提供了两种基本的调度逻辑,即 Eager 调度与 Lazy From Source。Eager 调度如其名子所示,它会在作业启动时申请资源将所有的 Task 调度起来。
这种调度算法主要用来调度可能没有终止的流作业。与之对应,Lazy From Source 则是从 Source 开始,按拓扑顺序来进行调度。
简单来说,Lazy From Source 会先调度没有上游任务的 Source 任务,当这些任务执行完成时,它会将输出数据缓存到内存或者写入到磁盘中。然后,对于后续的任务,当它的前驱任务全部执行完成后,Flink 就会将这些任务调度起来。这些任务会从读取上游缓存的输出数据进行自己的计算。这一过程继续进行直到所有的任务完成计算。
其中 Eager 调度适用于流作业,而Lazy From Source 适用于批作业。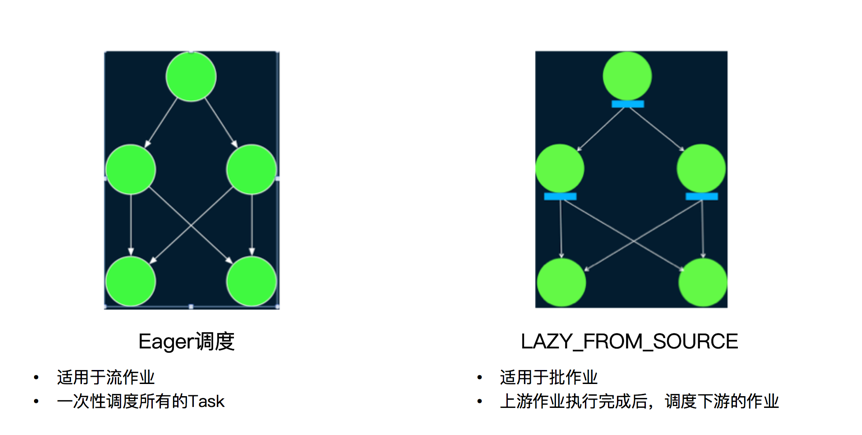
错误处理
在 Flink 作业的执行过程中,除正常执行的流程外,还有可能由于环境等原因导致各种类型的错误。整体上来说,错误可能分为两大类:Task 执行出现错误或 Flink 集群的 Master 出现错误。由于错误不可避免,为了提高可用性,Flink 需要提供自动错误恢复机制来进行重试。
对于第一类 Task 执行错误,Flink 提供了多种不同的错误恢复策略。如下图所示,第一种策略是 Restart-all,即直接重启所有的 Task。对于 Flink 的流任务,由于 Flink 提供了 Checkpoint 机制,因此当任务重启后可以直接从上次的 Checkpoint 开始继续执行。因此这种方式更适合于流作业。第二类错误恢复策略是 Restart-individual,它只适用于 Task 之间没有数据传输的情况。这种情况下,我们可以直接重启出错的任务。
该策略会直接重启所有的 Task。

该策略只适用于 Task之间不需要数据传输的作业,对于这种作业可以只重启出现错误的 Task。
由于 Flink 的批作业没有 Checkpoint 机制,因此对于需要数据传输的作业,直接重启所有 Task 会导致作业从头计算,从而导致一定的性能问题。为了增强对 Batch 作业,Flink 在1.9中引入了一种新的Region-Based的Failover策略。在一个 Flink 的 Batch 作业中 Task 之间存在两种数据传输方式,一种是 Pipeline 类型的方式,这种方式上下游 Task 之间直接通过网络传输数据,因此需要上下游同时运行;另外一种是 Blocking 类型的试,如上节所述,这种方式下,上游的 Task 会首先将数据进行缓存,因此上下游的 Task 可以单独执行。基于这两种类型的传输,Flink 将 ExecutionGraph 中使用 Pipeline 方式传输数据的 Task 的子图叫做 Region,从而将整个 ExecutionGraph 划分为多个子图。可以看出,Region 内的 Task 必须同时重启,而不同 Region 的 Task 由于在 Region 边界存在 Blocking 的边,因此,可以单独重启下游 Region 中的 Task。
基于这一思路,如果某个 Region 中的某个 Task 执行出现错误,可以分两种情况进行考虑。如图 8 所示,如果是由于 Task 本身的问题发生错误,那么可以只重启该 Task 所属的 Region 中的 Task,这些 Task 重启之后,可以直接拉取上游 Region 缓存的输出结果继续进行计算。
另一方面,如图如果错误是由于读取上游结果出现问题,如网络连接中断、缓存上游输出数据的 TaskExecutor 异常退出等,那么还需要重启上游 Region 来重新产生相应的数据。在这种情况下,如果上游 Region 输出的数据分发方式不是确定性的(如 KeyBy、Broadcast 是确定性的分发方式,而 Rebalance、Random 则不是,因为每次执行会产生不同的分发结果),为保证结果正确性,还需要同时重启上游 Region 所有的下游 Region。
如果是由于下游任务本身导致的错误,可以只重启下游对应的 Region。
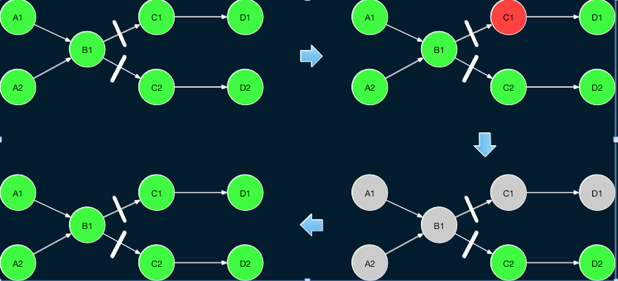
如果是由于上游失败导致的错误,那么需要同时重启上游的 Region 和下游的 Region。实际上,如果下游的输出使用了非确定的数据分割方式,为了保持数据一致性,还需要同时重启所有上游 Region 的下游 Region
除了 Task 本身执行的异常外,另一类异常是 Flink 集群的 Master 进行发生异常。目前 Flink 支持启动多个 Master 作为备份,这些 Master 可以通过 ZK 来进行选主,从而保证某一时刻只有一个 Master 在运行。当前活路的 Master 发生异常时,某个备份的 Master 可以接管协调的工作。为了保证 Master 可以准确维护作业的状态,Flink 目前采用了一种最简单的实现方式,即直接重启整个作业。实际上,由于作业本身可能仍在正常运行,因此这种方式存在一定的改进空间。
参考: